
16/01/2024
Data ingestion tools facilitate the process of collecting data from a variety of sources and integrating them into a single target, sometimes more. The framework created by these data ingestion tools standardizes and enhances these processes by making data extraction easier and enabling a vast protocol arsenal of data transport techniques.
The cumbersome procedure of manually coding individual data ingestion pipelines for each source of data can be substituted with a data ingestion tool. By helping users efficiently deliver data to ETL (extract, transform, load) tools and other data integration tools, or load data from multiple sources into a data warehouse directly, data processing is accelerated.
What is Data Ingestion?
Data ingestion is the process of collecting, importing, and processing raw data from various sources into a system or storage repository for analysis and use. This crucial step ensures that data is available and structured appropriately for further analysis and decision-making.
In the realm of big data and analytics, data ingestion involves sourcing information from diverse origins such as databases, logs, sensors, and external feeds. The collected data may be in different formats, like structured databases, semi-structured JSON files, or unstructured text. During ingestion, the data is often transformed, cleaned, and enriched to make it consistent and meaningful.
Data ingestion tools streamline the movement of data while addressing issues like scalability and reliability. Efficient data ingestion tools are crucial for organizations to derive valuable insights, support business intelligence, and make informed decisions. It sets the foundation for downstream processes like data storage, analysis, and reporting, enabling businesses to harness the full potential of their data assets.
What to Look for in a Data Ingestion Tool
While some companies opt to construct their own data ingestion framework, the majority will discover that utilizing a data ingestion tool crafted by experts in data integration is a more convenient and, depending on the specific solution, a more cost-effective approach. Utilizing the appropriate data ingestion tool allows for the extraction, processing, and transmission of data from diverse sources to multiple data repositories and analytics platforms, facilitating the provision of data to BI dashboards and, ultimately, front-line business users in a more efficient manner and with reduced resource utilization.
It’s important to note that not all solutions are identical, and selecting the optimal data ingestion tool for your requirements can be challenging. When comparing data ingestion tools, various criteria should be taken into consideration, such as:
Speed: The capability to swiftly ingest data and transmit it to the intended destinations with the minimal latency suitable for each specific application or scenario.
Support for Different Platforms: The capability to establish connections with data repositories both on-site and in the cloud, and manage the diverse types of data that your organization is currently acquiring and may acquire in the future.
Scalability: The ability to expand the framework to manage extensive datasets and incorporate rapid in-memory transaction processing to facilitate the efficient delivery of high-volume data.
Impact on Source Systems: The capability to routinely access and retrieve data from source operational systems without negatively affecting their performance or their ability to carry out transactions.
Additional features worth considering are integrated CDC (change data capture) technology, support for executing lightweight transformations, and user-friendly operation.
Methods of Data Ingestion & Data Processing
The selection of data ingestion methods for your organization is influenced by your distinct business requirements and data strategy. Two primary factors in this decision-making process include the urgency with which you need to access your data and the types of data sources you are utilizing.
There are three primary approaches to data ingestion and data processing: batch, real-time, and lambda, which is a fusion of the first two.
Batch Processing
In batch processing, historical data is gathered and transmitted to the target application or system in predefined batches. These batches can be automated, scheduled, triggered by a user query, or initiated by an application.
The chief advantage of batch processing lies in its ability to facilitate intricate analysis of extensive historical datasets. Traditionally, batch processing has been considered simpler and more cost-effective than real-time ingestion, but contemporary data ingestion tools are rapidly altering this dynamic.
Batch processing is supported by ETL (extract, transform, load) pipelines. The transformation of raw data to align with the target system before loading allows for methodical and precise data analysis in the designated repository.
If you require timely, near-real-time data but your data integration framework impedes the use of stream processing, micro-batching becomes a viable option. Micro-batching involves breaking down data into small increments and ingesting them incrementally, creating a simulation of real-time streaming.

Real-Time Processing
In the realm of real-time processing, also termed stream processing, streaming pipelines continuously move data in real-time from source to target. Unlike batch loading, each piece of data is promptly collected and transmitted from source systems as soon as it is identified by the ingestion layer.
One notable advantage of stream processing is the ability to analyze or report on the entire dataset, including real-time data, without the need to wait for IT to perform the extraction, transformation, and loading of additional data. This approach allows for the triggering of alerts and events in other applications, such as a content publishing system for personalized recommendations or a stock trading app for buying or selling equities. Moreover, contemporary cloud-based platforms offer a more cost-effective and low-maintenance alternative compared to batch-oriented data ingestion pipelines.
As an illustration, Apache Kafka serves as an open-source data store optimized for ingesting and transforming real-time streaming data. Its speed is attributed to decoupling data streams, resulting in low latency, and its scalability is achieved by enabling data distribution across multiple servers.
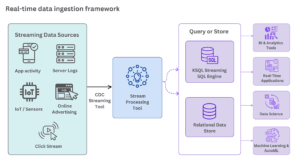
- To aggregate data sources and link them to a stream processor, a CDC (change data capture) streaming tool is employed. This tool consistently monitors transactions and redo logs, facilitating the movement of changed data.
- Data ingestion tools like Apache Kafka or Amazon Kinesis enable processing of streaming data on a record-by-record basis, either sequentially and incrementally or over sliding time windows.
- Utilizing data ingestion tools such as Snowflake, Google BigQuery, Dataflow, or Amazon Kinesis Data Analytics allows for filtering, aggregating, correlating, and sampling of data. This enables real-time queries using a streaming SQL engine like ksqlDB for Apache Kafka. Additionally, this data can be stored in the cloud for future use.
- With a real-time analytics tool, you can conduct analysis, data science, machine learning, or AutoML without waiting for data to reside in a database. As mentioned earlier, the ability to trigger alerts and events in other applications, such as personalized recommendations in a content publishing system or buying and selling equities in a stock trading app, is also facilitated.
Lambda Architecture
The ingestion process based on Lambda Architecture is a fusion of both batch and real-time methodologies. Lambda comprises three layers. The initial two layers, namely batch and serving, index data in predefined batches. The third layer, known as the speed layer, indexes any data not yet processed by the slower batch and serves layers in real-time. This dynamic maintains a continuous equilibrium among the three layers, ensuring that data is complete and available for querying with minimal latency.
This approach offers the advantages of both batch and real-time processing, providing a comprehensive view of historical batch data while concurrently reducing latency and mitigating the risk of data inconsistency.
Data Ingestion Tools
Qlik Replicate
Qlik Replicate stands out as a distinctive tool for data replication and ingestion, offering high-speed connectivity to gather data from diverse enterprise sources, including major relational databases and SAP applications. This versatile data replication platform is user-friendly, supporting easy installation, and is compatible with Hadoop distributions for data ingestion or publication, as well as Kafka message brokers. This all-encompassing tool facilitates tasks such as data migration from SQL Server to Oracle Database, ETL offload to Hadoop environments, and real-time streaming of multi-sourced data to Kafka message brokers, subsequently fueling big data platforms like Couchbase.
Furthermore, Qlik Replicate features in-memory streaming technology to enhance data movement efficiency and advanced CDC technology for capturing and ingesting data changes from source systems like Oracle and SQL Server without compromising operational performance.

Apache Kafka
Apache Kafka comprises a storage layer and a compute layer that seamlessly integrates efficient, real-time data ingestion, streaming data pipelines, and storage across distributed systems. In essence, this facilitates the simplified streaming of data between Kafka and external systems, allowing for the easy management of real-time data and scalability within any infrastructure setup.
Real-time Processing at Scale
The Kafka Streams API serves as a robust, lightweight library enabling on-the-fly processing, allowing for tasks such as aggregation, creation of windowing parameters, and performing joins of data within a stream, among other capabilities. This platform, developed as a Java application on top of Kafka, preserves your workflow without the need for additional clusters to maintain.
Durable, Persistent Storage
Functioning as an abstraction of a distributed commit log commonly found in distributed databases, Apache Kafka provides resilient storage. It can serve as a ‘source of truth,’ distributing data across multiple nodes for a highly available deployment within a single data center or across multiple availability zones.
Publish and Subscribe
At the core of Apache Kafka lies an immutable commit log, to which you can subscribe and publish data to any number of systems or real-time applications. This system is highly scalable and fault-tolerant, constituting a robust distributed infrastructure.
Azure Data Factory/Azure Data Explorer
The data ingestion pipeline on Azure Data Factory is used to ingest data to utilize with Azure Machine Learning. Data Factory offers the functionality to easily extract, transform, and load (ETL) data. After the data transformation and loading into storage, it can be used to train your machine learning models in Azure Machine Learning.
Azure Data Explorer performs initial data validation and converts data formats when necessary. Further manipulation of data includes tasks such as schema matching, organization, indexing, encoding, and compression. Once the data is ingested, it becomes available for querying.
Azure Data Explorer provides options for both queued ingestion and streaming ingestion.
Ingest data into your database tables using commands, the ingestion wizard, or data ingestion tools like LightIngest. To ingest your own data, you can select from a range of options, including ingestion tools, connectors to diverse services, managed data ingestion pipelines, programmatic ingestion using SDKs, and direct access to ingestion.
The ingestion wizard: This tool allows for the rapid ingestion of data by creating and adjusting tables from various source types. Based on the data source in Azure Data Explorer, the ingestion wizard automatically suggests tables and mapping structures. It can be utilized for one-time ingestion or to establish continuous ingestion through Event Grid on the container to which the data was ingested.
LightIngest: This is a command-line utility designed for ad-hoc data ingestion into Azure Data Explorer. The utility is capable of pulling source data from a local folder or an Azure blob storage container.
Data Ingestion Tools with Technoforte
Seamlessly capturing, validating, and transforming data from diverse sources using data ingestion tools, we pave the way for a streamlined and efficient data journey.
Efficient Data Processing: Technoforte ensures swift and accurate data processing, allowing clients to harness insights in real-time.
Customized Solutions: Tailored to meet unique business needs, our services offer flexibility and scalability, ensuring a perfect fit for any organization.
Seamless Integration: With our expertise, clients experience seamless integration of data from various platforms, providing a comprehensive view for informed decision-making.
Enhanced Data Quality: We prioritize data integrity, employing rigorous validation processes to ensure high-quality data, minimizing errors and discrepancies.
Cost-Effective Operations: We optimize resource utilization, providing a cost-effective solution without compromising on performance.
Choose Technoforte to revolutionize your data handling. From ingestion to insights, we’re committed to empowering businesses through efficient data management.
Technoforte is a data analytics services and consulting company, including implementing data ingestion tools. We have 21+ years of Business Intelligence implementation experience using cutting edge tools such as Tableau, Microsoft BI, Qlik and Snowflake. Besides data ingestion, we offer the following services:
- Data Warehousing
- Data Analytics & Design
- Predictive Analytics
- Big Data
- Data Integration and Data Migration
- Data Governance
Speak to our experts today to get a quote. Learn more here!
Read more about data visualization tools, data transformation tools, and data storage tools on our blog.
Technoforte is an IT Services company with over three decades of experience in the industry. Read more about our Managed IT services and IT Staff Augmentation services.



