What is a Data Lake?
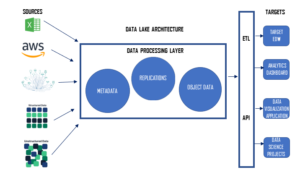
Structured, semi-structured, and unstructured data may all be stored at any scale in a data lake, a centralised data repository. It is a system that enables you to store all of your data centrally, without regard to its size or format. Raw data is stored in data lakes where it can subsequently be processed for analysis or other reasons.
How to successfully build a Data Lake?
Following these steps is often required to establish a data lake:
- Establish your data lake’s size: Determine the goal of your data lake, the type of data you want to store, the amount of data you want to store, and the tools and procedures you will need to employ before you begin developing your data lake. Tools and procedures will also need to be ascertained on how we can analyse this data.
- Pick a platform: Several cloud-based systems, like Amazon S3, Microsoft Azure Data Lake Storage, and Google Cloud Storage, are available for creating a data lake. Based on the needs, budget and current technological stack of your organisation, select a platform.
- Describe the process of data ingestion: Data ingestion is the procedure of gathering and importing data into the data lake. You must specify the steps involved in gathering data from diverse sources, including databases, apps, and IoT devices, and importing it into the data lake.
- Create a data governance strategy: Data governance is the process of controlling the data in the data lake’s accessibility, usability, integrity, and security. To make sure that your data is reliable, accurate, and accessible to authorised users, you need to create a data governance strategy.
- Create a data processing framework: To oversee the processing of data in the data lake, you must create a data processing framework. ETL (Extract, Transform, Load), data wrangling, and other procedures for handling the data should be specified in this analysis framework.
- Create data access policies that specify who has access to the data in the data lake, what data they can view, and what they are permitted to do with the data. To guarantee that only authorised individuals have access to the data and to avoid data breaches and data misuse, you must create data access policies.
Overall, setting up a data lake might be challenging, but it can also be a useful tool for organising and analysing large amounts of data.
Some leading Data Lake tools:
Some of the leading data lake tools are:
- Databricks – Key feature is Databricks eliminates data silos and has Data Lake + Data Warehouse clubbed into a single product
- Google Data Lake – Key feature is Google platform includes Hadoop and Apache Spark.
- AWS Cloud – Key feature is Amazon DynamoDB is built-in for better Metadata storage.
What is the difference between Data Lake v/s Data Warehouse?
Data lakes are a central repository that may store any sort of data, structured or unstructured, in its raw form, unlike data warehouses, which are meant to store structured data in a well organised and specified format. In terms of data storage options, scalability, and managing various data kinds, data lakes provide more flexibility.
Here are some of the key differences:
| Data Warehouse | Data Lake |
| Structured Data – Pre-defined Schema. ‘Schema on Data Write’ before storage approach. | Storage Schema is flexible and raw data in any format can be stored for future analysis. ‘Schema on Read’ approach. |
| Data is transformed, cleansed, structured and then stored. So process is time consuming. | Provides for iterative exploration of data. Ingestion of such ‘as-is’ data is fast. |
| Relationship between Columns and Tables is rigid. Data quality and consistency is high. | Accommodates Structured, unstructured and semi-structured data. |
| Typically, scalability is vertical with a pre-conceived business scenario. | Scalability is horizontal to enable data distribution across different scenario clusters. |
| Hold structured data, so is limited by vertical business scenarios and Schemas. | Can handle vast amount of data. Suitable for Big Data and high volume data ingestion. |
| Organized data and employs ETL (Extract, Transform and Load) process for data load. | Complex with varying data structures and formats. Employs ELT process for analysis. |
| Good for structured reporting, ad-hoc data query, consolidated view and building business intelligence applications. | Good for Big data, Data & Pattern Discovery, AI, ML, Data experiments data Insights and advanced analytics by Data Scientists. |
| Data Governance and Compliance. | Data Flexibility and speed. |
Both Data Lake and Data Warehouse complement each other, thus providing a fine balance between data governance and data flexibility.



